Prometheus operator를 이용한 Memcached 지표 수집 예제


이번 글에서는 prometheus에 대해 가볍게 소개하고, Prometheus operator를 이용해 memcached의 지표를 수집하는 예제를 만들어보겠다.
Prometheus 소개
프로메테우스(Prometheus)는 모니터링 시스템으로, 메트릭 정보를 주기적으로 수집해 시계열 DB(TSDB, TimeSeries DB)에 저장하고, PromQL(Query Language)을 이용한 시각화 및 추출을 지원한다.
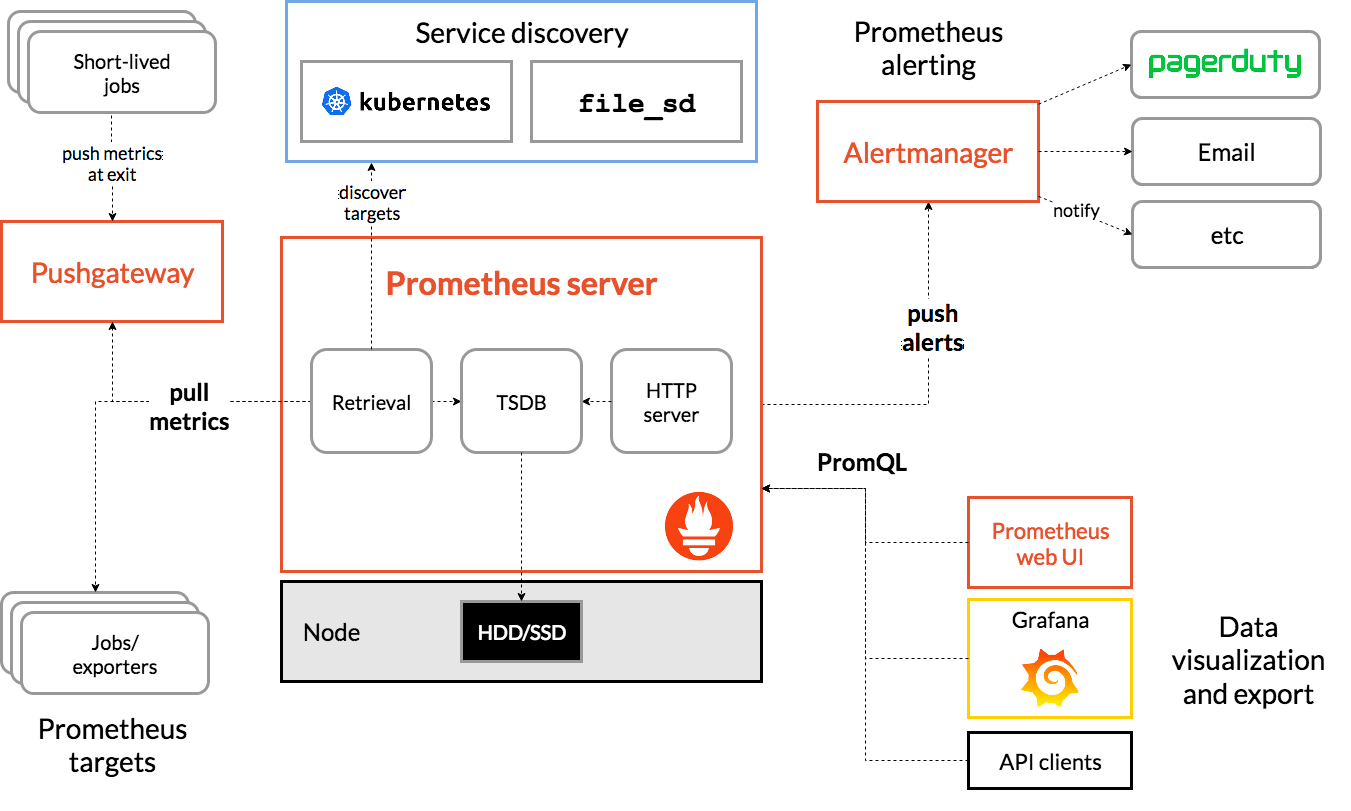
기본 구성은 이렇게 생겼고, 기본적으로는 메트릭을 긁어가는(scraping) 방식으로 동작한다.
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']수집할 엔드포인트와 주기 등은 scrape_configs에 명시해줘야 한다.
- Prometheus config: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
Exposition Format
# HELP http_requests_total The total number of HTTP requests.
# TYPE http_requests_total counter
http_requests_total{method="post",code="200"} 1027 1395066363000
http_requests_total{method="post",code="400"} 3 1395066363000
수집할 엔드포인트는 프로메테우스 text format에 맞춰 메트릭을 노출해야 한다.
메트릭의 type에는 counter, gauge 등이 있다.
- counter: 누적 값 / ex) 누적 http request 수
- gauge: 현재 값 / ex) CPU usage
이외에도 histogram, summary 등의 타입이 있다.
메트릭 타입 및 노출 형식에 대해 더 자세한 내용은 아래 문서를 참고한다.
- Prometheus metric types: https://prometheus.io/docs/concepts/metric_types/
- Prometheus exposition formats: https://github.com/prometheus/docs/blob/main/content/docs/instrumenting/exposition_formats.md
Remote Write
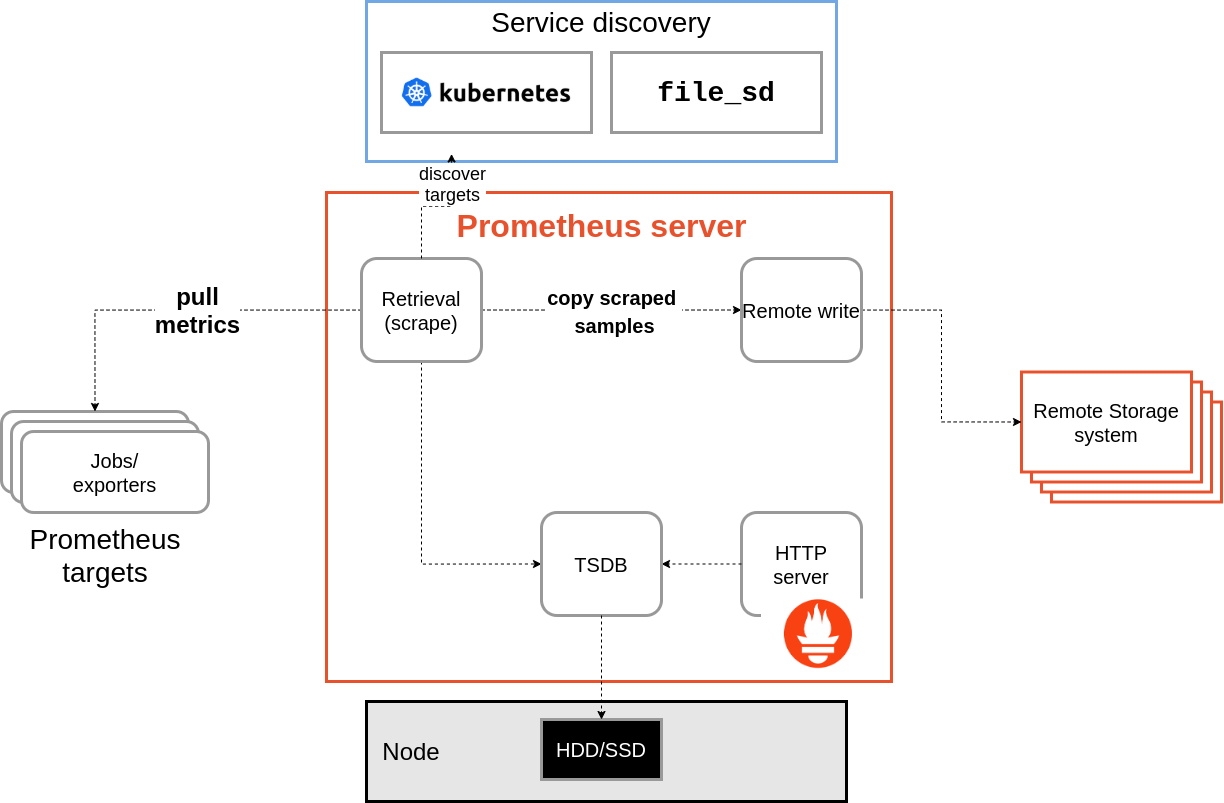
수집을 Prometheus로 하되, 저장은 내부 tsdb가 아닌 외부 스토리지(ex. GCP BigQuery 등)에 별도로 하고싶다면 Remote write라는 기능이 있다.
Prometheus를 딱 지표 수집 용도로만 쓰고 싶다면 이걸 쓰면 된다.
- Prometheus Remote write spec: https://prometheus.io/docs/concepts/remote_write_spec/
Prometheus Operator

k8s에서 operator(오퍼레이터)는 사용자 정의 애플리케이션 리소스를 말한다.
Prometheus operator를 이용하면 여러 Custom Resource(CR, 커스텀 리소스)를 사용할 수 있는데, 이중에서 Prometheus와 ServiceMonitor(서비스 모니터)를 사용해 메트릭을 수집할 수 있다.
ServiceMonitor는 특정 라벨이 붙어 있는 서비스를 찾아 메트릭 endpoint로 사용할 수 있도록 해주는 Custom Resource로, Prometheus 재기동 없이 유연한 scraping을 할 수 있다.
Prometheus Exporter
exporter는 메트릭을 특정 엔드포인트로 노출시켜주는 앱이다.
대부분의 exporter는 오픈소스 커뮤니티에 의해 관리되며, 몇몇 exporter는 Prometheus Github organization 안에 들어있기도 하다. memcached exporter는 prometheus org에 의해 관리되는 exporter 중 하나다.
- Exporters and Integrations: https://prometheus.io/docs/instrumenting/exporters/
대부분의 오픈소스들은 이미 exporter가 있기 때문에 "어떻게 메트릭을 노출할지"에 대해서는 고민하지 않아도 되며, 자체 앱서버의 경우(ex. Spring Boot), micrometer 및 actuator로 메트릭을 노출하는 것이 필요하다.
예제) Memcached exporter + ServiceMonitor
 sh-cho
sh-cho긴 설명이 끝났다. 직접 만들어보자. 참고로 예제 코드는 위 리파지토리에 전부 정리되어 있다.
memcached 서버가 여러대 있고, prometheus를 띄울 수 있는 k8s 클러스터가 있다고 가정해보겠다.
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install aaa bitnami/memcached
helm install bbb bitnami/memcached로컬 k8s 클러스터는 kind로 띄우면 되고, memcached는 위처럼 helm으로 띄운다.
LATEST=$(curl -s https://api.github.com/repos/prometheus-operator/prometheus-operator/releases/latest | jq -cr .tag_name)
curl -sL https://github.com/prometheus-operator/prometheus-operator/releases/download/${LATEST}/bundle.yaml | kubectl create -f -그 다음, 위 명령어로 Prometheus CRD들을 설치하고 operator를 default namespace에 설치한다. 그 다음부터 ServiceMonitor 등의 CRD를 사용한 커스텀 리소스를 만들 수 있다.
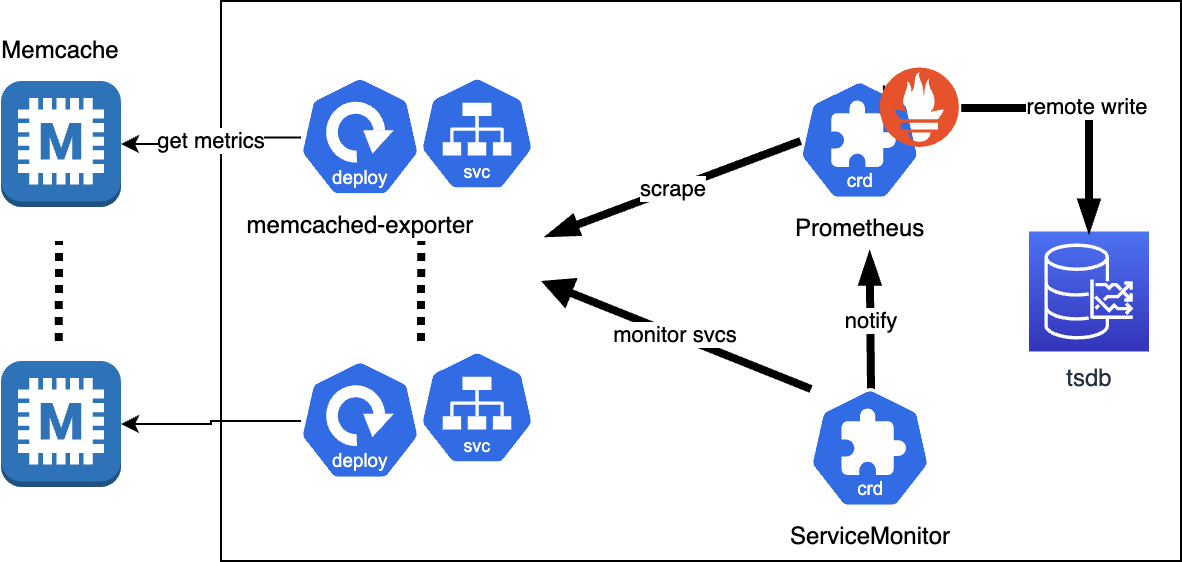
다음 이런식으로 k8s 리소스를 구성하면 끝이다.
멤캐시 한대에 exporter 파드 하나 + 서비스 하나씩인데, 예제 만들 때만 해도 multi-target 지원을 안해서 이렇게 했었다. (지금은 굳이 exporter를 여러개 만들 필요는 없어 보인다)
예제 리파지토리를 가보면 멤캐시 지표 수집 리소스를 helm chart로 정리해놨다
.
├── Chart.yaml
├── README.md
├── templates
│ ├── _helpers.tpl
│ ├── cluster_role.yaml
│ ├── cluster_role_binding.yaml
│ ├── copy.yaml
│ ├── prometheus.yaml
│ ├── service_account.yaml
│ └── service_monitor.yaml
└── values.yaml차트 구조는 위와 같다. Prometheus가 memcached exporter 파드로부터 지표 수집을 할 수 있도록 ServiceAccount 추가, Cluster Role 추가 등이 필요하다.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: memcached-exporter-service-monitor
namespace: {{ .Release.Namespace }}
labels:
name: memcached-exporter-service-monitor
exporter: memcached-exporter
spec:
selector:
matchLabels:
prometheus-exporter/target: memcached
namespaceSelector:
any: true
endpoints:
- port: metrics
interval: 5s
# In order to keep timeseries, need to drop unwanted labels
relabelings:
- regex: (container|endpoint|namespace|pod|service)
action: labeldrop
metricRelabelings:
- regex: (instance|job)
action: labeldrop
targetLabels:
- prometheus-exporter/host-and-portServiceMonitor는 prometheus-exporter/target: memcached 라벨이 붙은 서비스만 수집하도록 했다. 그리고 불필요한 라벨이 너무 많이 붙어서, 의미 없는 라벨들은 drop을 했다.
{{- range .Values.memcachedList }}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "prometheus-memcached-exporter.short-name" $ }}-{{ (split "." .host)._0 }}-{{ .port }}
namespace: {{ $.Release.Namespace }}
labels:
{{- include "prometheus-memcached-exporter.labels" $ | nindent 4 }}
spec:
selector:
matchLabels:
{{- include "prometheus-memcached-exporter.selectorLabels" $ | nindent 6 }}
template:
metadata:
labels:
{{- include "prometheus-memcached-exporter.labels" $ | nindent 8 }}
prometheus-exporter-0/host-and-port: "{{ .host }}_{{ .port }}"
spec:
containers:
- name: {{ $.Chart.Name }}
image: prom/memcached-exporter:v0.11.3
imagePullPolicy: IfNotPresent
ports:
- name: metrics0
containerPort: 9150
protocol: TCP
args:
- "--memcached.address={{ .host }}:{{ .port }}"
---
apiVersion: v1
kind: Service
metadata:
name: {{ include "prometheus-memcached-exporter.short-name" $ }}-{{ (split "." .host)._0 }}-{{ .port }}
namespace: {{ $.Release.Namespace }}
labels:
{{- include "prometheus-memcached-exporter.labels" $ | nindent 4 }}
prometheus-exporter/host-and-port: "{{ .host }}_{{ .port }}"
spec:
ports:
- port: 9151
targetPort: metrics0
protocol: TCP
name: metrics
type: ClusterIP
selector:
{{- include "prometheus-memcached-exporter.selectorLabels" $ | nindent 4 }}
prometheus-exporter-0/host-and-port: "{{ .host }}_{{ .port }}"
{{- end }}value 파일에서 멤캐시 하나당 deployment / service 하나씩 만들도록 한 파일이다.
앞서 말했지만 memcached-exporter가 multi-target 지원을 하기 때문에 필요하다면 적절히 수정하면 될 것 같다
memcachedList:
- host: "aaa-memcached.default.svc.cluster.local"
port: 11211
- host: "bbb-memcached.default.svc.cluster.local"
port: 11211values 파일은 이런식으로 작성해준다
helm install -f myvalues.yaml -n prometheus-exporter --create-namespace memcached-exporter .마지막으로 helm 차트로 배포하면 끝!
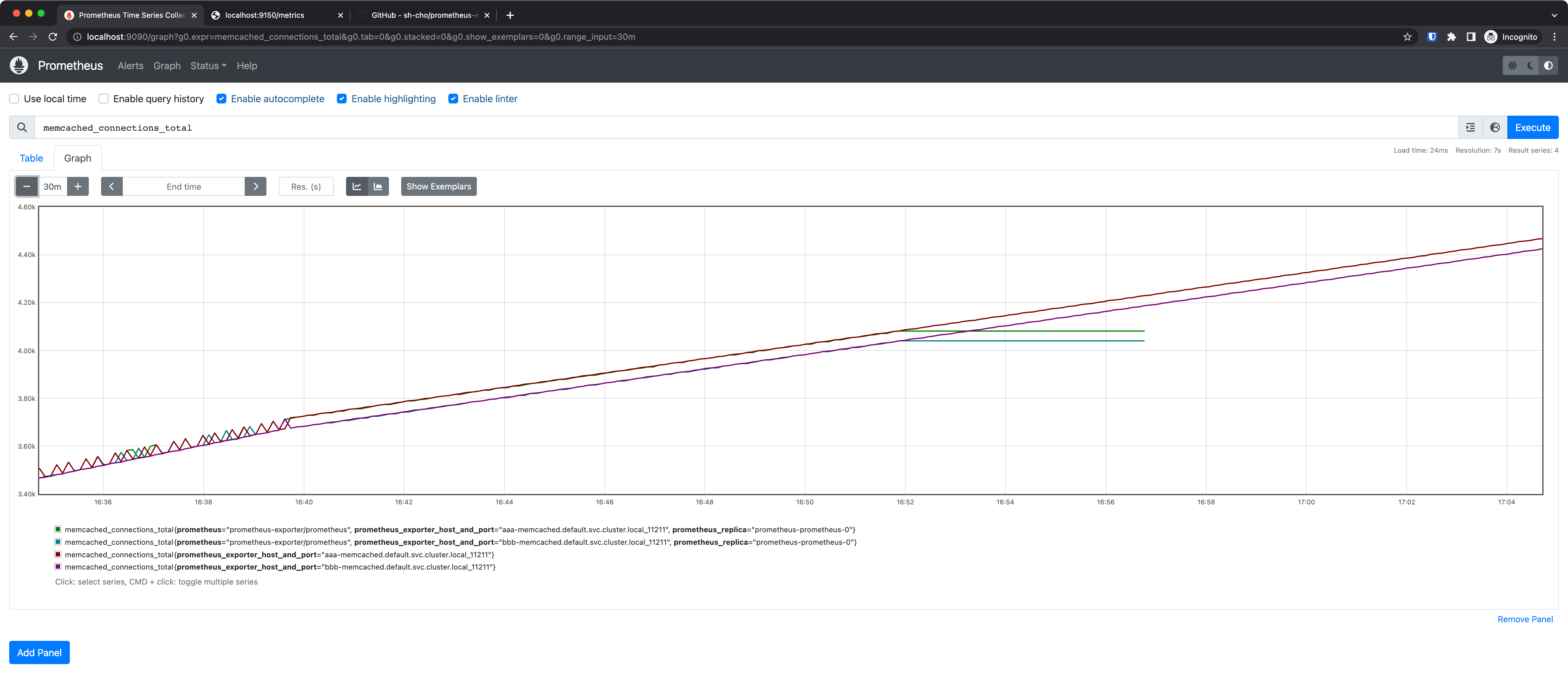
메트릭을 수집한 뒤 그래프로 보면 위처럼 나온다.
위 두개 시리즈의 prometheus_replica처럼 의미 없는 라벨은 떼는게 나은 것 같다.